AI-Driven Automation
Task Automation
Automate repetitive tasks and complex workflows.
ETL & Data Pipelines
Build robust data ingestion and transformation systems.
Web Scraping Solutions
Extract valuable data from the web at scale.
Automated Reporting
Generate key insights with auto-generated reports.
Custom AI Development
AI Agents & Chatbots
Develop intelligent agents and conversational AI.
Computer Vision Systems
Build systems for advanced image and video analysis.
NLP Solutions
Leverage natural language processing for text-based tasks.
Reinforcement Learning
Create custom agents for control and optimization.
Automation & Efficiency
Publication Classifier
Classifies research papers & predicts publishability using SciBERT & Sentence-BERT.
Mermaid Mind
Online MermaidJS editor & AI-powered tool for creating diagrams.
ApexAI Writer
Chrome extension as a writing assistant for generating high-quality messages and emails.
Intelligent Platforms
ChatStore
Intelligent product chatbot for a personalized shopping experience.
Smart Health AI
ML system predicting 8 diseases with user-driven retraining via FastAPI & MLflow.
MediXpert AI
AI-driven healthcare solution for diagnostics, patient engagement & data security.
Advanced AI Applications
Synthetic Swara
Deep learning for classifying Indian classical music swaras & predicting pitch.
ToxicGPT
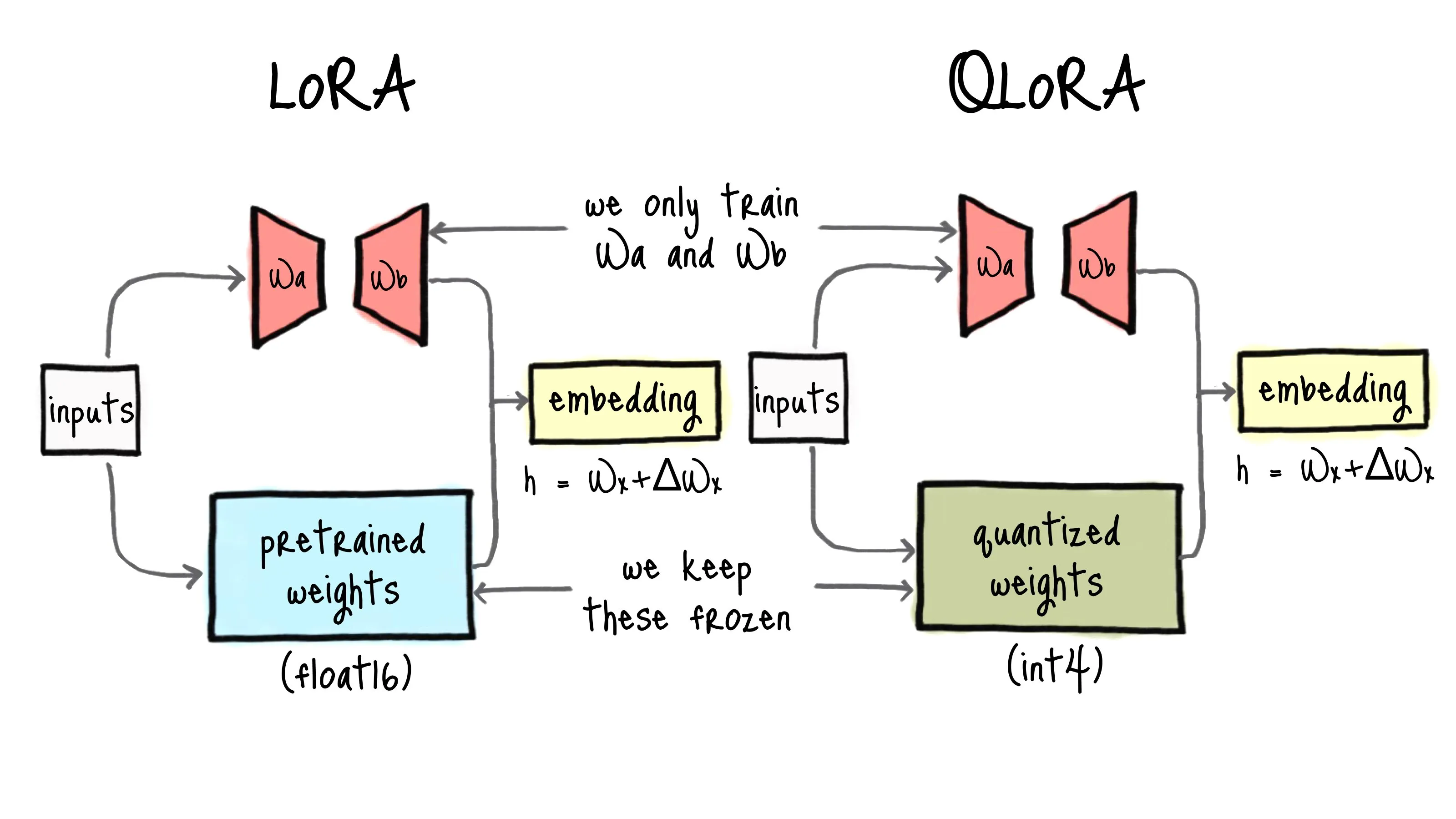
Fine-tuned GPT-2 with QLoRA for controlled toxic text generation & multimodal experiments.
View All Projects
Explore our full portfolio of AI solutions.
Our GitHub Profile
See our open-source contributions and more projects.
Education
AI Tutoring Systems
Personalized learning with intelligent tutoring systems.
Automated Assessment
Reduce grading time with NLP-powered tools.
Smart Content Delivery
Adaptive platforms that adjust to learner pace.
Telecommunication
Network Fault Detection
Real-time anomaly detection in 5G/4G networks.
Customer Churn Prediction
Forecast and reduce customer attrition using ML.
Traffic Optimization
Optimize bandwidth and performance with AI insights.
AI-Powered Platforms to Automate, Analyze & Accelerate Growth
AI-Driven Automation
Custom AI Development
Intelligent Platforms
Showcasing Our Innovations: Real-World AI Solutions
Automation & Efficiency
Intelligent Platforms
Advanced AI Applications
- Synthetic SwaraDeep learning for classifying Indian classical music swaras & predicting pitch.
- ToxicGPTFine-tuned GPT-2 with QLoRA for controlled toxic text generation & multimodal experiments.
- View All ProjectsExplore our full portfolio of AI solutions.
- Our GitHub ProfileSee our open-source contributions and more projects.